From April 11, 2022 to April 12, 2022

In Order to prepare the participation to the next Jsalt workshop in JHU, Baltimore, the LIUM welcomed the ESPERANTO team in Le Mans for two days of intensive brainstorming around their project "Multi-lingual Speech to Speech Translation for Under-Resourced Languages" .

For this first event, many partners were present:

In order for the ESPERANTO members to arrive fully prepared in the future Jsalt workshop, the different tasks were divided between the sub-groups and refined during these two days.
This first meeting also allowed to create the cohesion of the team around social events such as the discovery of the historic quarter - Cité Plantagenêt offered by Le Mans Métropole.
Next meeting will take place in Avignon, on 2-3 of June.
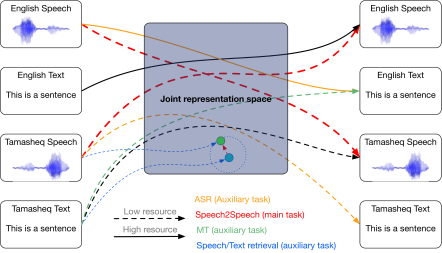
Seamless communication between people speaking different languages is a long term dream of humanity. Artificial intelligence aims at reaching this goal. Despite recent huge improvements made for Machine Translation, Speech Recognition and Speech Translation, Speech to Speech Translation (SST) remains a central problem in natural language processing, especially for under-resourced languages. A solution to this problem is to gather and share information across modalities and large resource languages to create a common multi-modal multi-lingual representation space that could then be used to process under-resourced one through transfer learning, as depicted in Figure 1.
